

【制作したきっかけ】
AIデータサイエンス演習という講義にて自然言語処理に関するAIを用いたアプリを作成することになり、自然言語処理の中でも固有表現抽出に関するアプリを深層学習チームで作成しました。
【説明】
Doctor in Your Pokectは英文で文章を入力すると病名やその症状に関する部分を固有表現抽出しわかりやすく印をつけます。そしてのれらの情報から、病名を予測した結果を返します。
【機能】
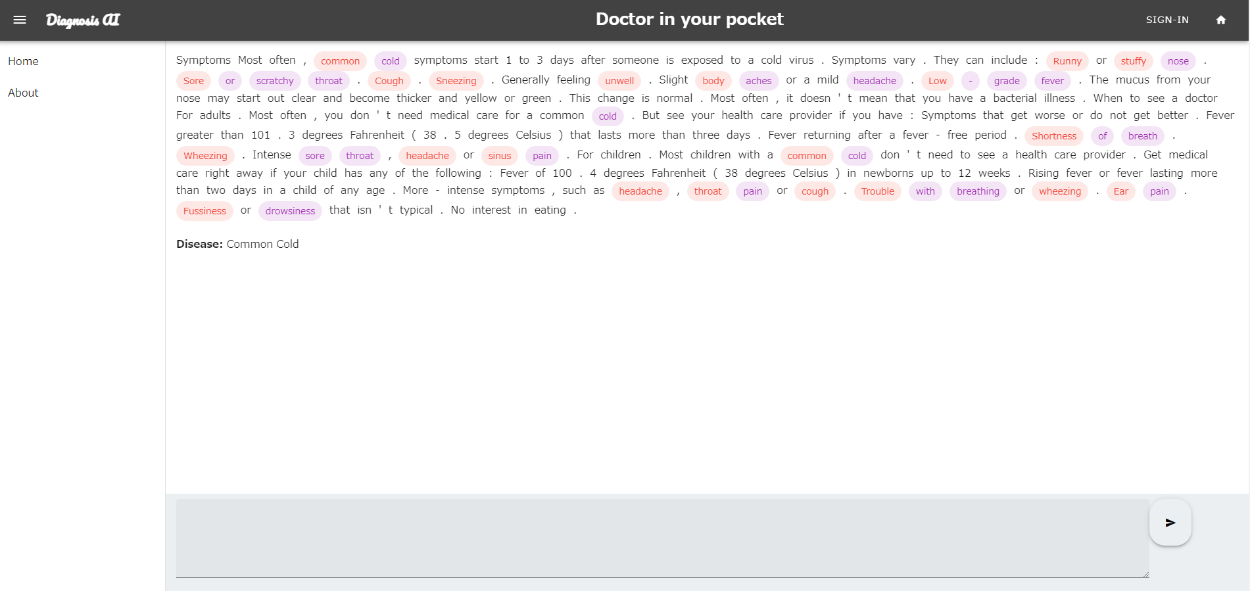
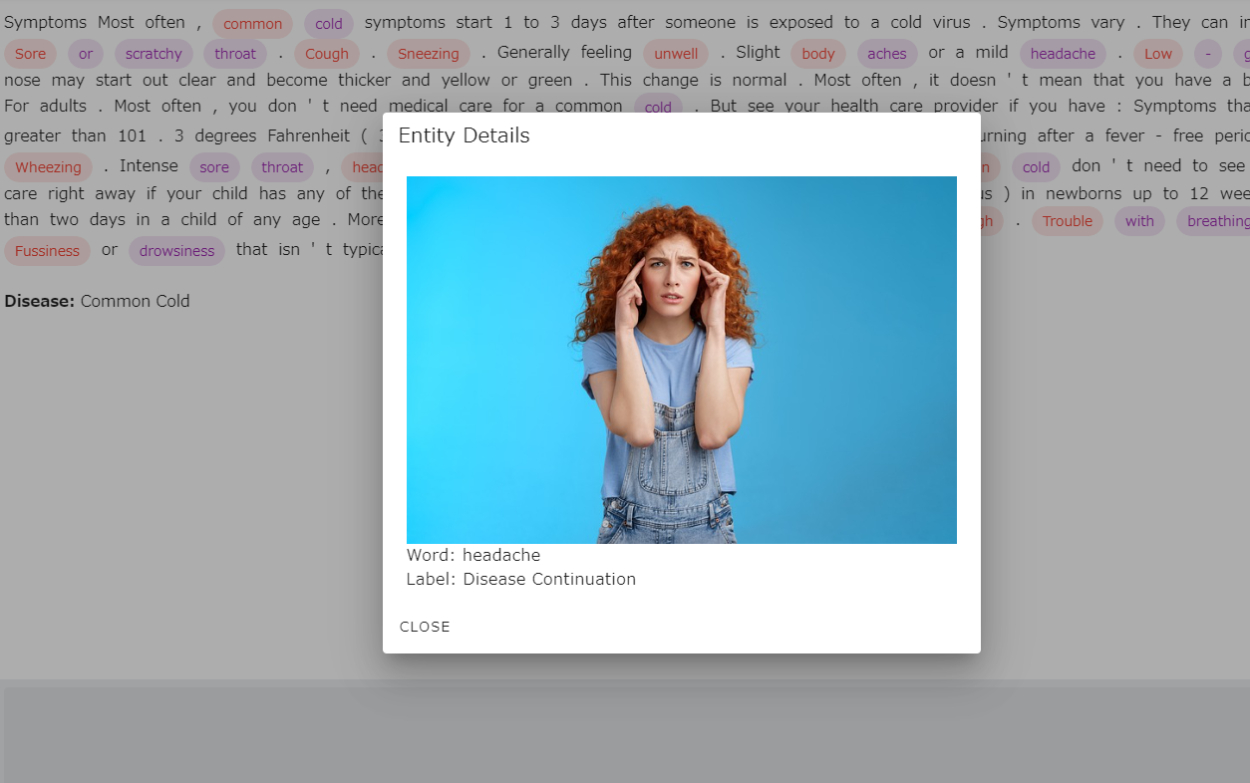
文章を送信してその文章から固有表現を抽出しわかりやすく印をつけたものを画面に表示します。また、印がつけられた単語をクリックするとその単語に関する画像やラベリングを確認できます。最終的にそれらの固有表現から病名を予測します。
【開発環境】
使用言語: python javascript
使用フレームワーク: django Vue.js Vite
開発環境: windows
【担当箇所】
もともと深層学習チームで固有表現抽出のアプリを作成した後にそのアプリを病気予測仕様に変更したので元々のアプリの担当と仕様変更後の担当に分けて書きます。
元々のアプリの担当
- フロントエンドの記述(送信画面や画像表示,文章表示など)
仕様変更後の担当
- フロントエンドの記述
- バックエンドの固有表現抽出の部分と病名予測AIの実装
【開発期間】
構想に1ヶ月、コーディングなどに3ヶ月
【工夫した点】
元々チームで開発した固有表現抽出のアプリをフォークして病名診断機として再開発しました。元々のアプリの開発にもフロントエンドの部分やバックエンドの一部を担当しましたが、再開発にあたってバックエンドのAPIや使用するAIモデルなどを一新しました。
工夫した点はユーザーが見やすいようなUIをViteを用いて構築することと、シングルページアプリケーションにすることでchatGPTのように何をすればいいのかわかりやすくしたことです。
【苦労した点】
フロントエンド
フロントエンドの苦労した点はAPIからレスポンスを受けとった際に画面にテキストを表示したいので親コンポーネントや子コンポーネント間のデータの送信、親子関係にないコンポーネント間の通信に苦労しました。
バックエンド
バックエンド側で苦労した点はどのような形式でデータを送信するかなどの設定に苦労しました。また、固有表現抽出されたデータを整形するのにも苦労しました。
【固有表現抽出機】
固有表現抽出にはhagging face hubで公開されている病名や症状に関するモデルを使用させていただきました。
【病名予測AI】
病名予測AIはBertの分類機をhagging face hubに公開されている病名と症状に関するデータセットを用いてファインチューニングして作成しました。
病名予測の流れは
- フロントエンドでユーザーが入力したテキストをAPIに送信する。
- バックエンド側でテキストを単語ごとに分割し固有表現抽出する。
- 固有表現抽出された病名や症状の単語を病名予測AIに入力し予測された病名を得る。
- 最後にこれらのデータをjson形式でフロントエンドに返し、描写する。
このような流れになっています。
使用させていただいたデータセット
今回作成した病名予測AIモデル
【改善点】
改善点としては病名予測の精度が低いことと40種類の病気しか予測できないことです。今回使用したデータセットが4000症例しかないことやデータセット内の病気に偏りがあるため更なる改良が必要と感じました。